第六課的中間開始講到這個road to the top
一共分為4個notebook, 感覺可以學到很多技巧
讓我們來慢慢研究
這是以水稻病害分類為主題,所以先來看一下資料長什麼樣
包含了10,407張(佔總體的75%)稻谷葉片圖像,分為十個類別(包括九種疾病和正常葉片)。每個圖像還有提供metadata,例如稻谷品種和年齡。任務是使用訓練數據集開發一個準確的疾病分類模型,然後將測試數據集中的3,469張(佔總體的25%)稻谷葉片圖像分類為九種疾病或正常葉片
train的欄位說明如下:
image_id - 唯一的圖像ID,對應到 train_images 目錄中
label - 稻谷疾病的類型,也是目標類別。共有十個類別,包括正常葉片
variety - 稻谷品種的名稱
age - 稻谷的年齡(以天為單位)
test_images - 包含了3,469張測試集圖像。
讓我們看一下sample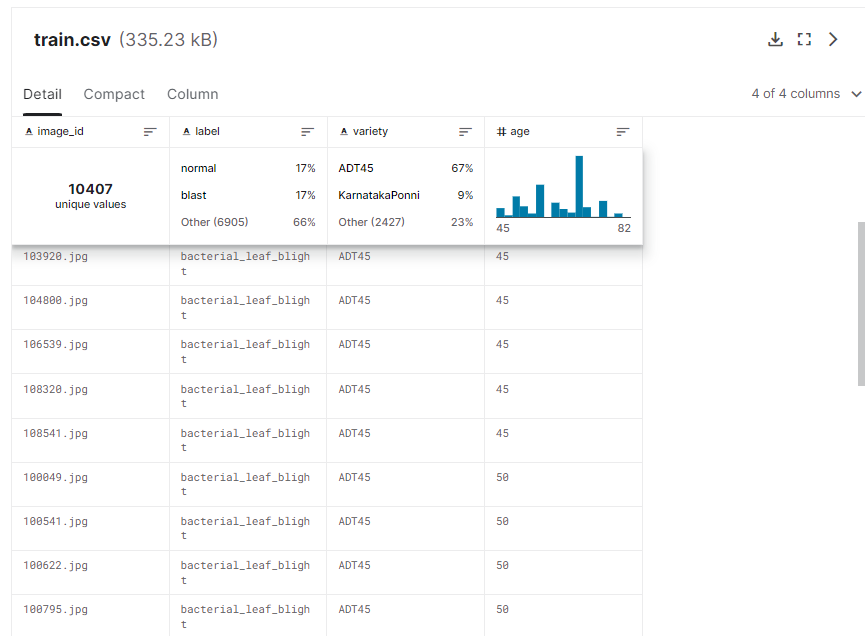
所以要預測的就是給一張新圖片,我們要label 出他是哪一種疾病的水稻
那知道比賽內容後,就來看看講師怎麼教我們登頂?
先來檢查一下我們的數據,圖片都長怎樣,大小都有一樣嗎?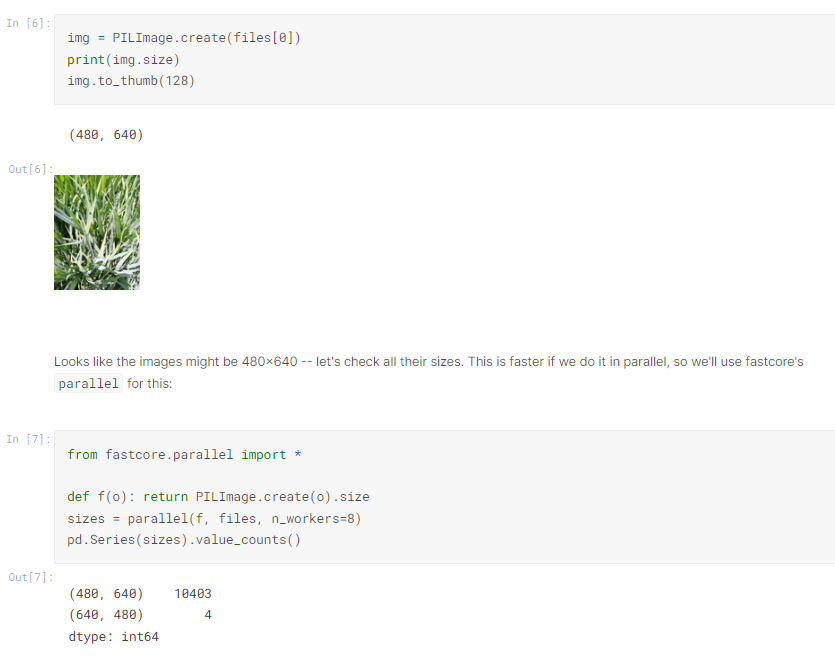
顯然kaggle 沒有對我們這麼好,有幾張不一樣的。
接下來先把image 都squish 到480*480

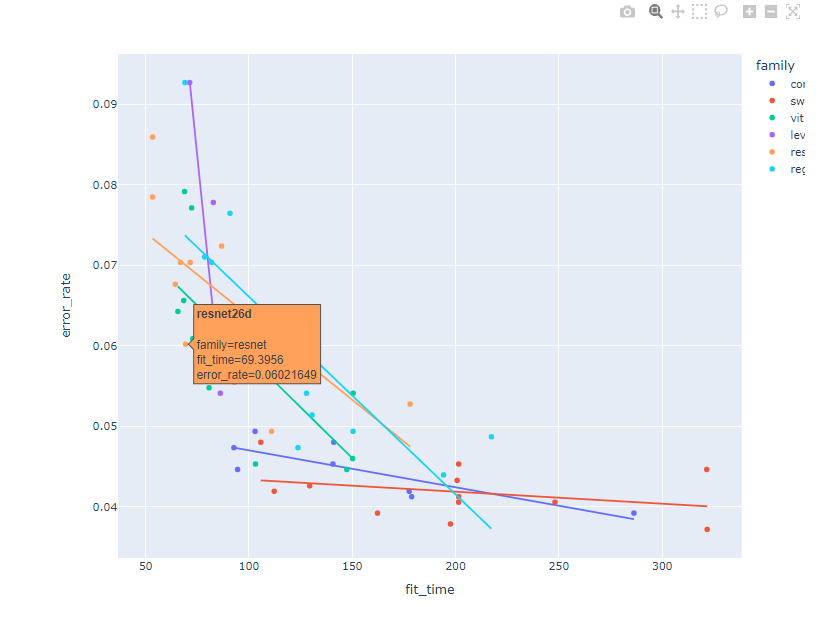
好了那我們先用一個model 來跑跑看,既然是影像,之前講師有一個notebook是關於影像model 的性能的,我們可以從中挑選一個出來跑跑看。講師挑的是resnet26d
現在看code ,以下選了model ,以及尋找建議起始的學習率
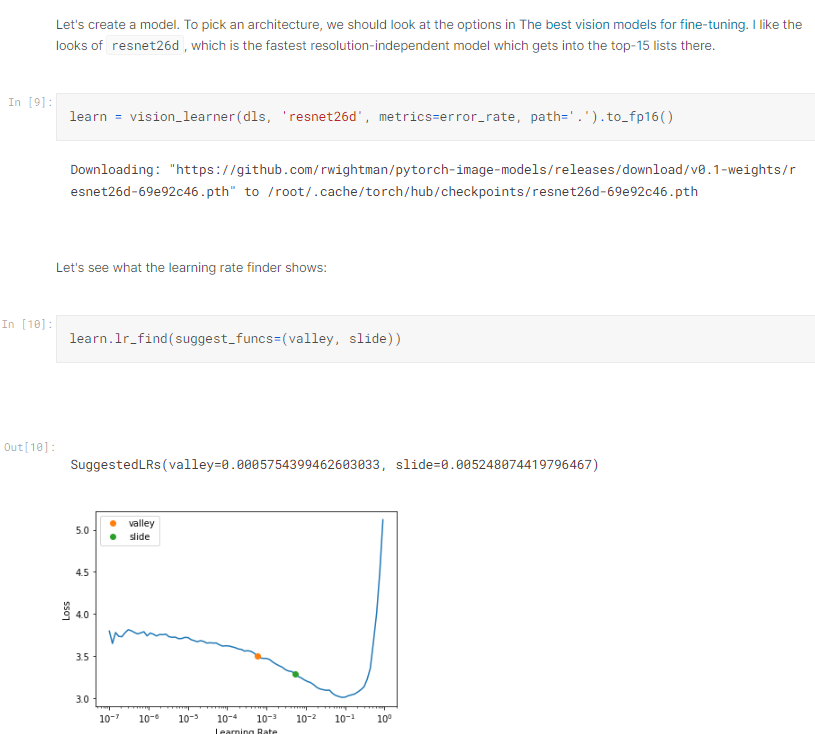
其中learn.lr_find() 函數中的 suggest_funcs 參數是什麼呢?
查了一下,是用於指定學習率尋找過程中的建議函數。這些函數用於分析學習率曲線,並提供建議的學習率範圍。
suggest_funcs 被設置為 (valley, slide),這意味著兩個不同的函數將被用於分析學習率曲線。
valley 函數:通常用於找到學習率曲線的谷底,就是錯誤率降低最快的區域
slide 函數:通常用於找到學習率曲線的滑坡區域,即錯誤率開始上升的區域。
還有很多的函數可以選,這個我們現在不用先了解,先跟著跑看看。
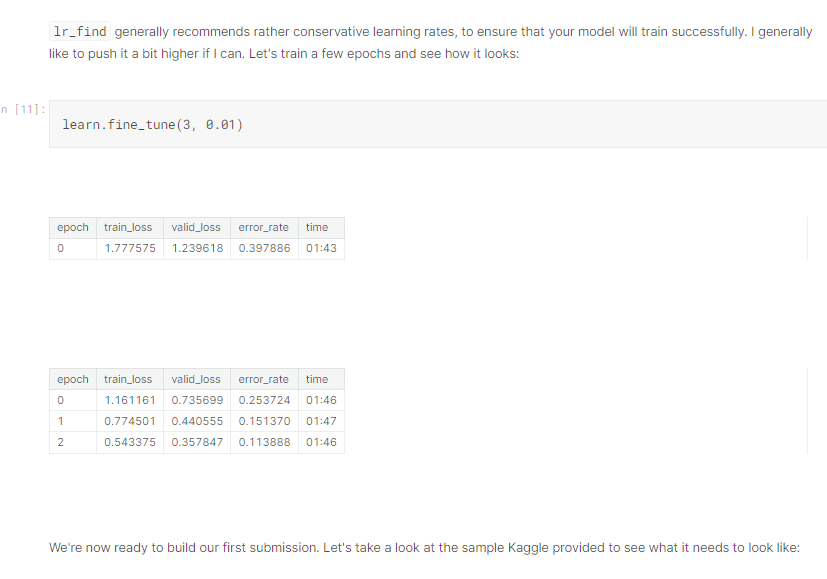
可以看到這邊的第1個參數是3,代表跑了3個epoch, 第2個參數是0.001就是學習率,那怎麼不是剛才跑出來的建議學習率呢?這邊講師說他通常會習慣比建議的學習率高一點點。
接下來就是做預測了!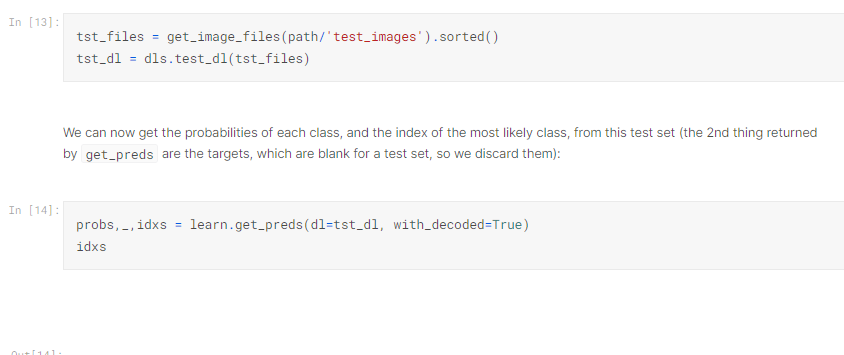
這邊把圖片load 進來做預測,可以看到他跑出幾個類別。
後面就只是做資料處理,怎麼把這些跟類別資料做mapping。
這樣就跑完登頂之路(一)
好像太簡單了XD?
後面還有登頂之路(二)(三)(四)
我們可以看看講師有什麼招數來優化這些步驟!
今天先這樣


 iThome鐵人賽
iThome鐵人賽